|
I am a Ph.D. candidate at Mila starting Fall 2023, where I'am advised by Prof. Aishwarya Agrawal. |

|
|
I am interested in following research topics: learning from multiple data modalities, language understanding in autonomous systems during navigation, explainable deep learning, mutli-object tracking, improving robustness to domain shifts and adversarial attacks, learning in low-data regimes, and ensemble learning. |
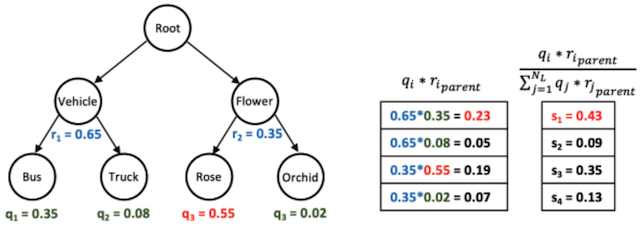 |
Kanishk Jain, Shyamgopal Karthik, Vineet Gandhi NeurIPS, 2023 pdf / code We investigate the problem of reducing mistake severity for fine-grained classification. Our novel approach of Hierarchical Ensembles (HiE) utilizes label hierarchy to improve the performance of fine-grained classification at test-time using the coarse-grained predictions. |
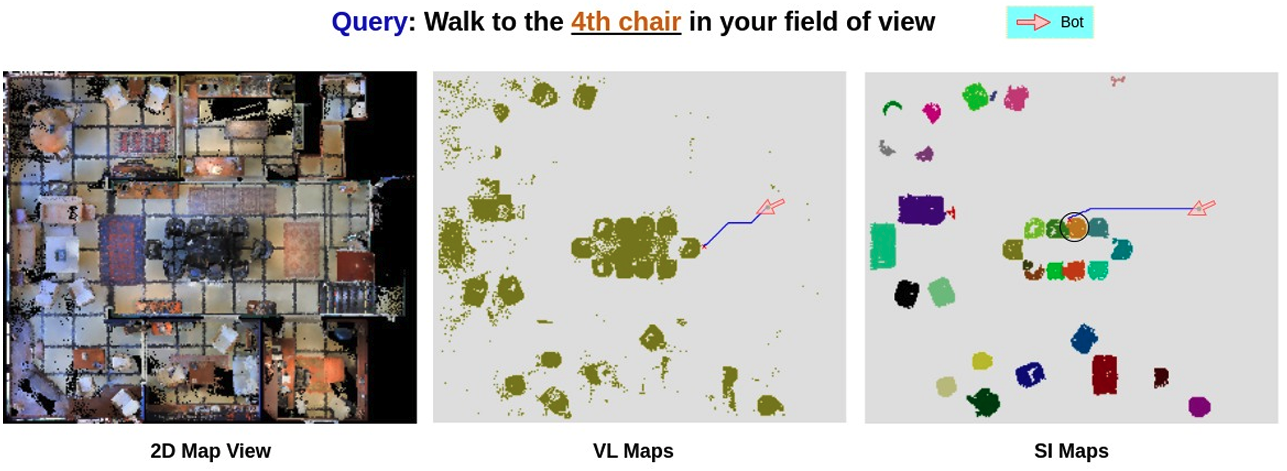 |
Laksh Nanwani, Anmol Agarwal, Kanishk Jain, Raghav Prabhakar, Aaron Monis, Aditya Mathur, Krishna Murthy, Abdul Hafez, Vineet Gandhi, K. Madhava Krishna ROMAN, 2023 pdf / bibtex We introduce a novel instance-focused scene representation for indoor settings, enabling seamless language-based navigation across various environments. Our representation accommodates language commands that refer to specific instances within the environment. |
|
|
Kanishk Jain, Shyamgopal Karthik, Vineet Gandhi CVPR Workshop, 2023 pdf / code / bibtex We investigate the problem of reducing mistake severity for fine-grained classification. Our novel approach of Hierarchical Ensembles (HiE) utilizes label hierarchy to improve the performance of fine-grained classification at test-time using the coarse-grained predictions. |
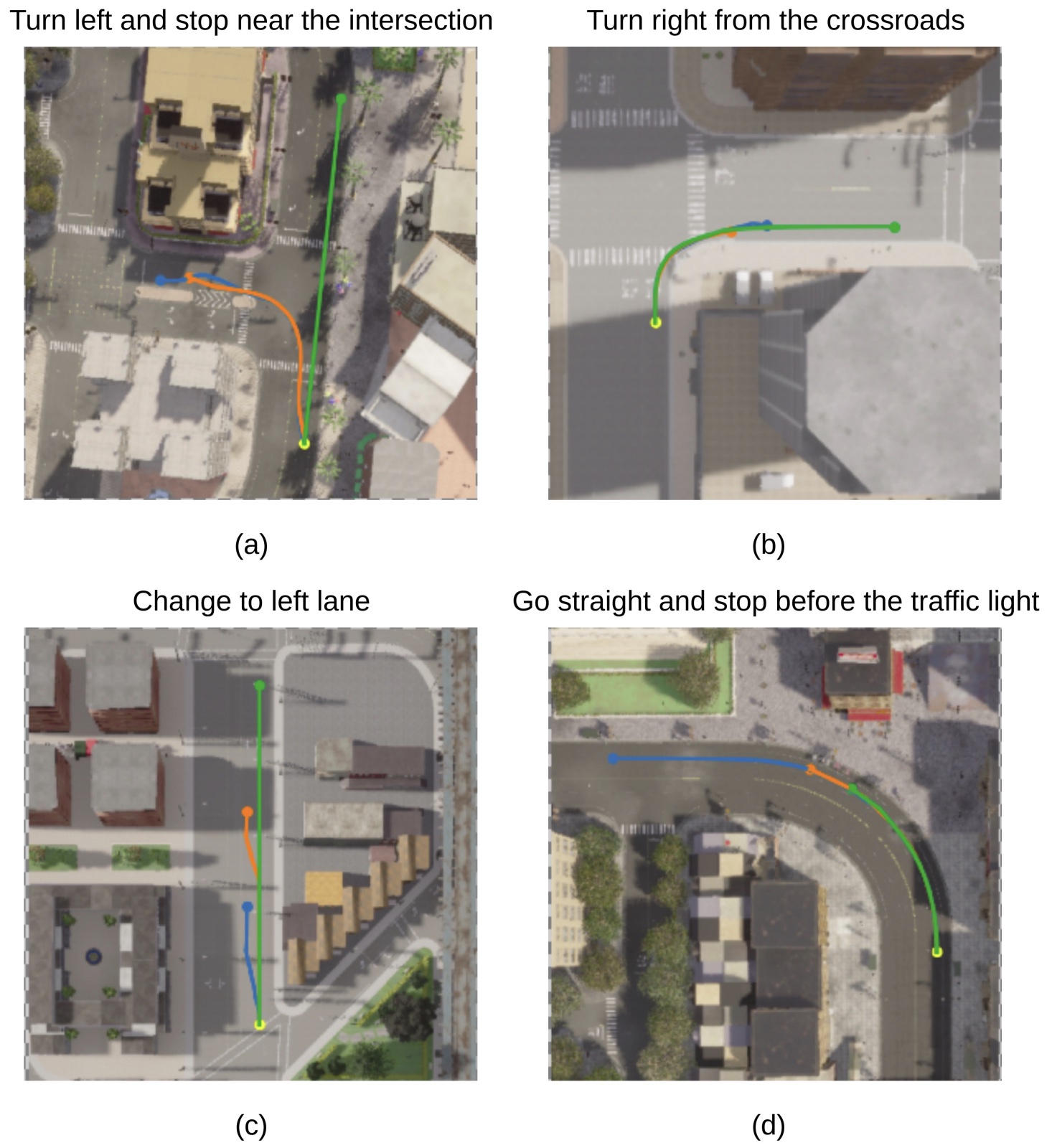 |
Kanishk Jain*, Varun Chhangani*, Amogh Tiwari, K Madhava Krishna, Vineet Gandhi ICRA, 2023 pdf / bibtex We investigate the Vision-and-Language Navigation problem in the context of autonomous driving in outdoor settings. We explicitly ground the navigable regions corresponding to the textual command and use them directly as guidance for the navigation stack. |
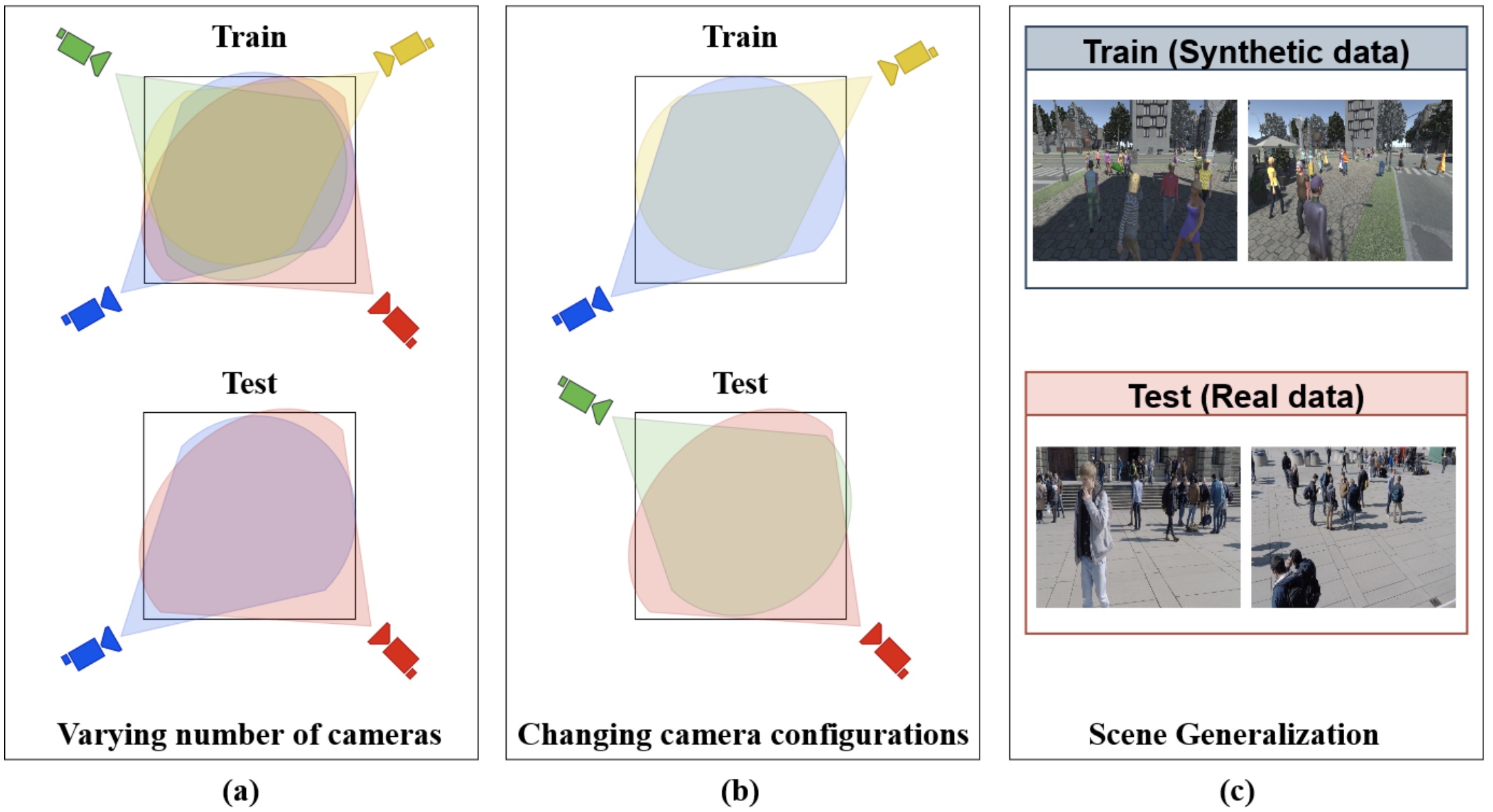 |
Jeet Vora, Swetanjal Dutta, Kanishk Jain, Shyamgopal Karthik, Vineet Gandhi WACV workshop, 2023 pdf / code/ bibtex We find that existing state-of-the-art models show poor generalization by overfitting to a single scene and camera configuration. We formalize three critical forms of generalization and propose experiments to evaluate them. |
 |
Kanishk Jain, Vineet Gandhi ACL Findings, 2022 pdf / code/ bibtex We investigate Referring Image Segmentation, which outputs a segmentation map corresponding to the natural language description. We propose a novel architecture to effectively capture all forms of multi-modal interactions synchronously. |
 |
Kanishk Jain*, Nivedita Rufus*, Unni Krishnan R Nair*, Vineet Gandhi, K Madhava Krishna IROS, 2021 pdf / code/ bibtex We propose a novel visual-grounding-based approach to language-guided navigation which brings interpretability and explainability to Vision Language Navigation task. |
|
Template Courtesy of Jon Barron |